This post describes how to selfhost an LLM using Llamacpp
You can try the model, further down the page.
The model used is Phi-3.5-mini-instruct-Q8_0
The server has an Intel(R) Core(TM) i5-8400 CPU @ 2.80GHz processor and 2 * 8GB DDR4 2400 MHz. It is less powerfull than your run of the mill modern laptop.
The server runs llamacpp inside a docker container. Here is the compose file
services:
llama-api:
image: ghcr.io/ggml-org/llama.cpp:server
container_name: llama-cpp-api
tty: true
restart: unless-stopped
ports:
- "5002:8080"
volumes:
- ./models:/models
command:
- "--model"
- "/models/Phi-3.5-mini-instruct-Q8_0.gguf"
- "--host"
- "0.0.0.0"
- "--port"
- "8080"
- "--ctx-size"
- "4096"
- "--threads"
- "4"
- "--batch-size"
- "512"
- "--no-mmap"
A simple test
# IP of server on LAN and port from compose file
$uri = "http://192.168.0.37:5002/v1/completions"
$body = @{
model = "local-model"
prompt = "Write a haiku about llamacpp"
max_tokens = 50
temperature = 0.8
} | ConvertTo-Json
(Invoke-RestMethod -Uri $uri -Method Post -ContentType "application/json" -Body $body).choices[0].text
Sending that request produces this log
prompt eval time = 164.85 ms / 1 tokens ( 164.85 ms per token, 6.07 tokens per second)
eval time = 9579.90 ms / 50 tokens ( 191.60 ms per token, 5.22 tokens per second)
total time = 9744.74 ms / 51 tokens
A processing time of almost 10 seconds and hitting token max. This is not using streaming. With streaming it will seem quicker as respons get printed as its generated
Phi-3.5-mini-instruct-Q8_0 is dumb as rock compared to newer larger models, but still very useable with precise prompting. It but the server under stress
Here is the server under normal load. It has a total of 35 containers running, but most are idle the majority of the time

Here is the load while processing a prompt
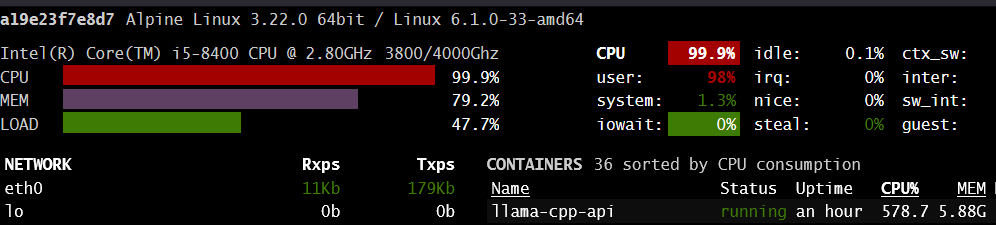
Screenshot are from the Glances service
Try it here!
When using try it now. There is a systemprompt of "You are a precise, technical assistant. Provide maximum information density with minimum word count. No conversational filler, no greetings, direct entry only."